

Procedural Lettrism
Procedural Lettrism
The GAN as a tool for obscuring symbols beyond recognition


This post will be an overview of using GANs to create lettrist artworks.
A great example of avant-garde being indistinguishable from trolling.
But anyway, that clip is more about sonic deviation from established units of communication, whereas the technique in focus here is about visual deviation, specifically by way of Generative Adversarial Networks (GANs).
If you are uninterested in the technical stuff, just scroll to the next hyphen break.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
GANs are types of neural networks, which are seemingly the primary algorithms behind artificial intelligence. They are designed to be fed large amounts of data, and to dissect that data in search of distinct components, which can be linked together to comprise distinct ensembles of components.
In the case of a handwriting recognition algorithm, a given scrawling would simultaneously be passed through a number of checkpoints, each one screening for a particular visual component, such as a curve or an edge or a dot, that would help distinguish that scrawling as a real letter. 3Blue1Brown has a great video on YouTube explaining this.
A distinct visual object, such as a human face, can be broken down into dozens or hundreds of visual units, i.e. particular arrangements of pixels, that can be reliably and unambiguously screened for by these algorithms.
In fact they aren’t unlike the human visuo-cognitive wetware in that sense. That is, we don’t recognize a “T” as a “T” if its edges are disrupted too much, if there is too much curvature, etc.
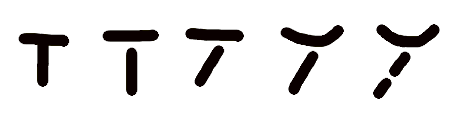
Neural networks are some of the most important algorithms in society, as they allow for things like dynamic facial recognition, handwriting recognition, etc.
GANs, again a type of neural network, are another step forward for artificial intelligence, namely for so-called unsupervised learning.
It’s a schizoid arrangement in a GAN: one side generates novel data intended to pass some specified criterion, and the other side decides whether or not the data passes. The “generator” and the “discriminator” respectively. The “adversity” between these sides is the reason for its name.
Using a particular GAN called VQGAN+CLIP, you can input a text prompt and receive novel images that the algorithm thinks qualify under said prompt. This particular GAN creates a series of iterative attempts, and automatically stitches them into an .mp4 file.
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
You can also input an initial image, a point of departure which the GAN can nudge toward the text prompt. In the case of the .gif at the top of this post, which I converted from the .mp4, the initial image was this:

and the textual input was
particle | waveform | electron microscopy
which resulting in this sequence of image iterations:

If you search like terms in google images, you get things like:
You can also input target images, as an alternative/complement to the text prompts, to give the GAN something to nudge the iteration towards.
In this next example, I took this as the initial image:

This as the text prompt (the |’s separate distinct prompts):
psyche | organic machine | roots | complexity | digital
And this actual photo as the target image, a cross section of neurons which I don’t think are dyed but rather digitally colored:

And this was the result, after 200 iterations/frames:

Personally I think the avant-garde has more or less run its course in terms of cultural disruption, but if there is a frontier yet it arguably consists of this kind of hybrid creative process, the algorithm being an appendage to the mind of the artist, a technical extension of the will, etc.
Thanks to:
Katherine Crowson, for creating VQGAN+CLIP